Handwritten Digit Recognition
Introduction
Handwritten digit recognition refers to a computer's capacity to recognize human handwritten digits from a variety of sources, such as photographs, papers, and touch displays, and classify them into ten specified categories (0-9). In the realm of deep learning, this has been a topic of inexhaustible investigation.There are numerous applications for digit recognition, including number plate identification, postal mail sorting, and bank check processing. Because handwritten digit recognition is not an optical character recognition, I encounter numerous obstacles due to the various styles of writing used by different people.
The Dataset
The MNIST dataset, a well-known handwritten digit benchmark dataset, was utilized to train and test the suggested classification system in this study. Handwritten images of the ten digits make up the dataset (0 to 9). The photos have been normalized and are available in unsigned byte format. The MNIST dataset is a subset of a bigger dataset accessible from the National Institute of Standards and Technology (NIST), and it contains a total of 70000 data elements, with 60000 examples for training and 10000 examples for testing.A 20x20 pixel matrix was used to represent the photos in the NSIT database. However, there were some gray levels in the photographs. In the MNIST dataset, this problem was handled by normalizing all of the 2020 handwritten images into 2828 images. The previous image's center of mass is determined, and the normalized image is then positioned inside the 2828 image in such a way that the center of mass is at the center. In the MNIST collection, several sample handwritten digits are shown below. It's also worth noting that the MNIST dataset is completely noise-free.

The MNIST Dataset
SUPPORT VECTOR MACHINE (SVM)
The Support Vector Machine (SVM) is a machine learning algorithm that is supervised. In this case, I plot data items in n-dimensional space, where n is the number of features, and a specific position indicates the value of a feature. I then classify the data by locating the hyperplane that separates the two classes. It will select the hyperplane that best separates the classes. SVM selects the extreme vectors that aid in the construction of the hyperplane. Support vectors represent extreme examples, which is why the technique is called Support Vector Machine.Both dense (numpy.ndarray and numpy.asarray) and sparse (any scipy.sparse) sample vectors are supported as input by the SVM in scikit-learn. SVC, NuSVC, and LinearSVC are scikit-learn classes that can conduct multi-class classification on a dataset. LinearSVC was utilized in this paper to classify MNIST datasets that used a Linear kernel has built.
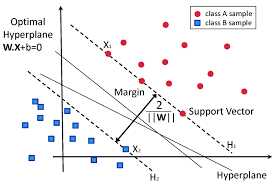
Support Vector Machine
MULTILAYERED PERCEPTRON (MLP)
A feedforward artificial neural network called a multilayer perceptron (MLP) is a type of feedforward artificial neural network (ANN). It has three layers: an input layer, a concealed layer, and a final output layer. Each layer is made up of numerous nodes, which are also known as neurons, and each node is connected to the nodes of the following layer. There are three layers in a basic MLP, however, the number of hidden layers can be increased to any number depending on the problem, with no limit on the number of nodes. The input and output layers' nodes are determined by the number of attributes and apparent classes in the dataset, respectively. Due to the unpredictable nature of the model, the number of hidden layers or nodes in the hidden layer is impossible to determine and must be chosen empirically.Handwritten digits recognition is implemented using the Keras module to generate an MLP model of Sequential class and add respective hidden layers with distinct activation functions to take an image of 28x28 pixel size as input. I added a Dense layer with varying specifications and drop-out layers after developing a sequential model, as seen in the image below. The block diagram is provided for your convenience. You can train a neural network in Keras by following these steps once you have the training and test data.
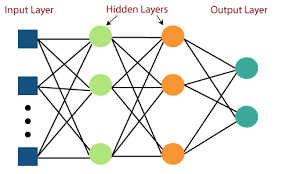
Multilayer Perceptron
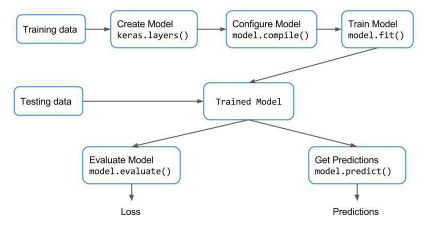
MLP training process
CONVOLUTIONAL NEURAL NETWORK (CNN)
CNN is a deep learning technique for image recognition and classification that is frequently used. It's a type of deep neural network that requires the least amount of pre-processing. It inputs the image in discrete chunks rather than a single pixel at a time, allowing the network to recognize ambiguous patterns (edges) more effectively in the image. Convolutional layers, Pooling layers (Max and Average pooling), Fully connected layers (FC), and normalizing layers are among the hidden layers found in CNN.Keras is used to implement handwritten digit recognition using a Convolutional Neural Network. It is a free and open-source neural network library for creating and implementing deep learning models. I used a Sequential class from Keras, which allowed to build the model layer by layer. The input image's dimensions are 28 (length), 28 (width), and 1 (height) (Number of channels).
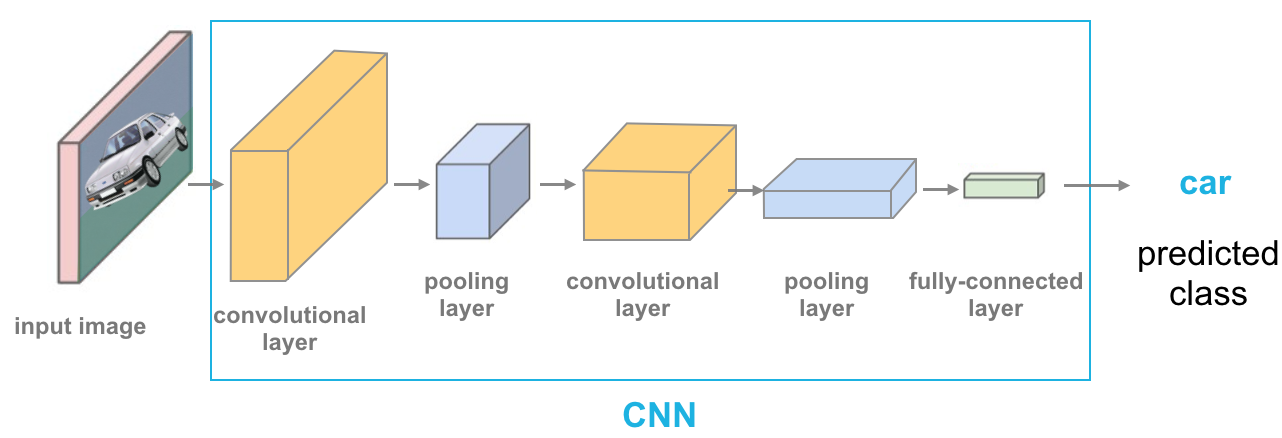
Convolutional Neural Network
Results
After building all three algorithms, SVM, MLP, and CNN, I compared their accuracies and execution times using experimental graphs to gain a better understanding. All of the models listed above have had their Training and Testing Accuracy taken into account. After testing all of the models, I discovered that SVM has the most accuracy on training data, whereas CNN has the highest accuracy on testing data. I also compared the execution times to acquire a better understanding of how the algorithms work. In general, an algorithm's execution time is proportional to the number of operations it has completed. So, to acquire the best result, I trained our deep learning model for 30 epochs and SVM models according to norms. The SVM took the shortest amount of time to execute, whereas CNN took the longest.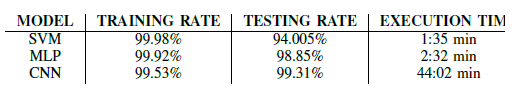
Analysis of different models in comparison
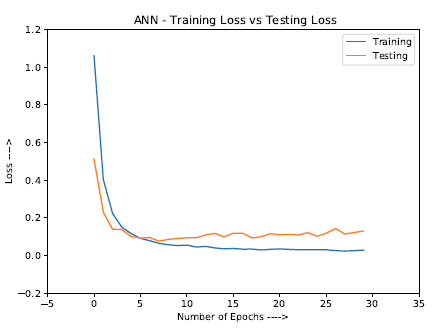
Loss rate v/s Number of epochs in MLP
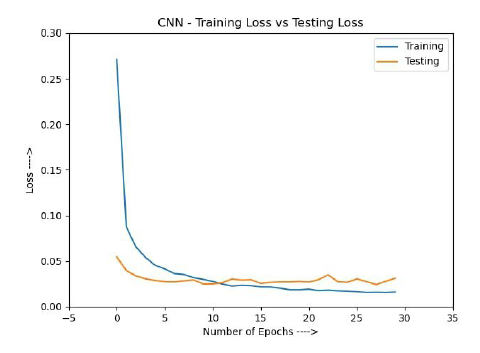
Loss rate v/s Number of epochs in CNN
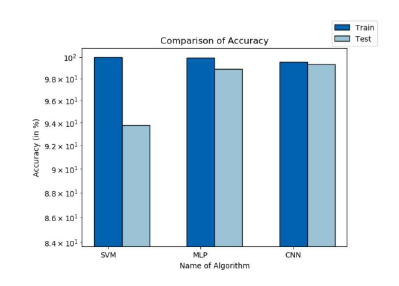
Comparison of accuracy
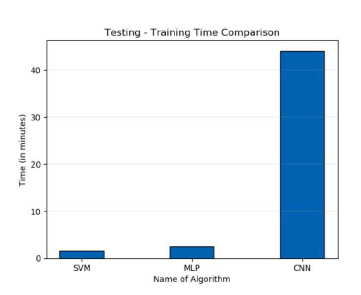
Comparison of training time
Finally, using MNIST datasets, I constructed three models for handwritten digit recognition based on deep and machine learning algorithms in this study. I compared them based on their attributes to determine which one was the most accurate. Support vector
machines are one of the most basic classifiers, which is why they're faster than other algorithms and, in this case, deliver the highest training accuracy rate. However, due to their simplicity, they can't categorize complicated and ambiguous
images as accurately as MLP and CNN algorithms can.
For handwritten digit recognition, I discovered that CNN provided the best accurate results. As a result, I may infer that CNN is the best choice for any form
of prediction task involving picture data. Following that, I concluded that increasing the number of epochs without changing the configuration of the algorithm is pointless due to the limitation of a particular model, and I observed that
after a certain number of epochs, the model begins overfitting the dataset and gives a biased predictions.
For the full document, code, and references I used, you may check the full file in the GitHub link provided at the bottom